在真实环境中的安全测试面临无法克服的高成本和伦理问题,因此利用仿真环境加速测试是一个在科学和产业上都具有重要意义的方向🚶♂️➡️♥︎。
——赵鼎
3月9日上午🧑🏿,第17期杏耀学术沙龙在线上如期举行🚶🏻🫅🏻。本期活动荣幸地邀请到了卡内基梅隆大学机械工程系赵鼎教授为我们线上作题为《可信赖的AI及其在自动驾驶中的应用》的报告🧑🏻🌾🔱。

本次活动由杏耀(杏耀)助理研究员龚江涛主持,杏耀官方视频号和b站同步直播,当日线上逾1200次观看,目前共计触达人数近2300人👨👧👦。
讲者介绍

赵鼎博士毕业于密歇根大学安娜堡分校,现任职于卡内基梅隆大学机械工程系助理教授😕,并在计算机科学系、机器学习系和机器人研究所兼任研究工作🤲🏿,他的重点研究方向是可信人工智能的理论和实践🧏♂️,及其在自动驾驶汽车🦉🏇🏻、智能制造🧓🏽、智能交通、助理机器人、医疗诊断和网络安全等方面的应用。赵教授2022年入选《麻省理工科技评论》“35岁以下科技创新35人”(中国区),曾获得National Science Foundation CAREER Award、Ford University Collaboration Award🧑🏿🎄、Carnegie-Bosch研究奖🤸🏿♂️、Struminger教学奖以及Adobe、博世和丰田的工业奖学金。此外,他还与谷歌大脑、亚马逊🧒🏿、福特、Uber、IBM、Adobe、博世和劳斯莱斯等领先工业伙伴合作🤷♂️。
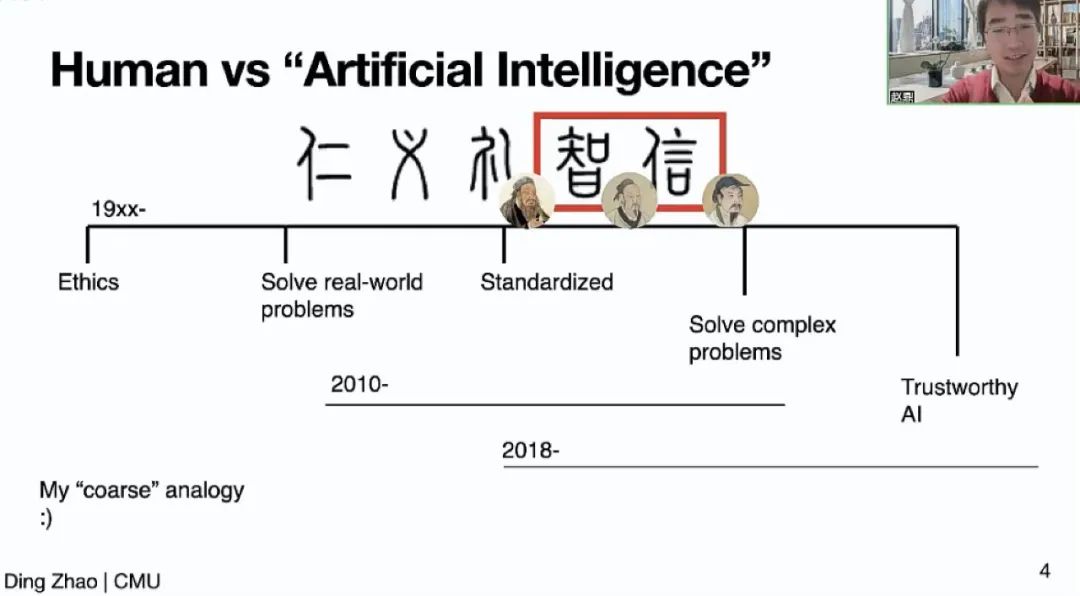
赵鼎教授以一个非常有趣的类比视角引出可信赖人工智能🤷♀️:中国传统儒家文化中的五常“仁、义、礼、智、信”并不是同时被提出的:孔子提出了“仁、义、礼”👮🏻🧓🏽,200年后,战国风云变化,要解决复杂事物,孟子提出了“智”,又一百年后,大汉一统,“信”最后被纳进五常🍓。赵鼎教授以此类比近十年来备受关注的深度学习🤦🏼♂️,展现近几十年来随着人工智能的发展,大家开始重视可信赖的算法和模型的趋势。
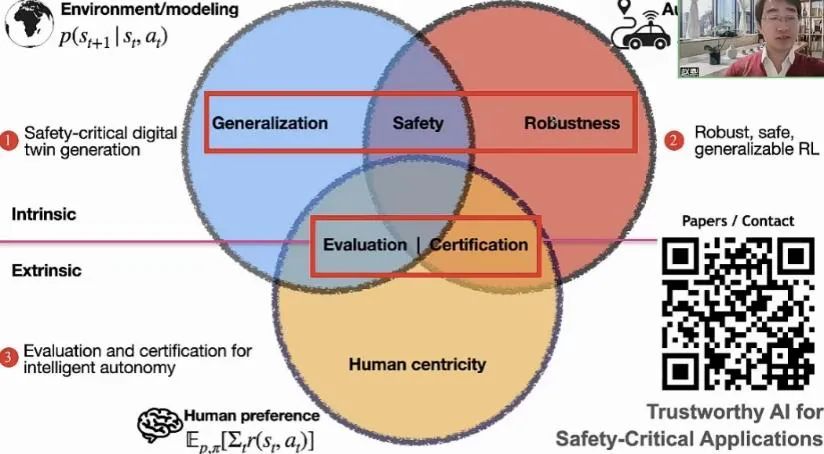
赵鼎教授接着介绍其近期研究的宏观方向👧🏻,主要关注在“感知与环境建模”👨🏿🌾、“自主决策”和“人类偏好”三个方面🔵:在感知方面📗,主要关注算法的泛化性🙍,研究重点是研究如何生成对安全性意义重大的数字孪生;在决策方面,主要关注算法的鲁棒性🤵🏿♀️𓀆,聚焦安全可靠的强化学习算法;在人因方面🚚🧑🏼🏭,主要关注如何设计“以人为本”的算法✅,重点关注如何基于人类偏好设计评测。同时这三方面的交集🫓,也引出一些前沿的科学问题,比如泛化性和鲁棒性的交集问题是系统的安全性🚺👩🏽🌾,泛化性和人因的交集问题是如果按照人类偏好去评价算法👩🏻💼🤱🏿,鲁棒性和人因的交集问题是如何有效的形式化验证算法的可靠性🤸🏽。
这次报告就这三方面展开。赵教授还指出😞,以人为本的算法研究本身就包含很多细分领域,比如公平🌊、隐私、可释性等。虽然这些不是这场报告的重点,但是都十分重要💼。
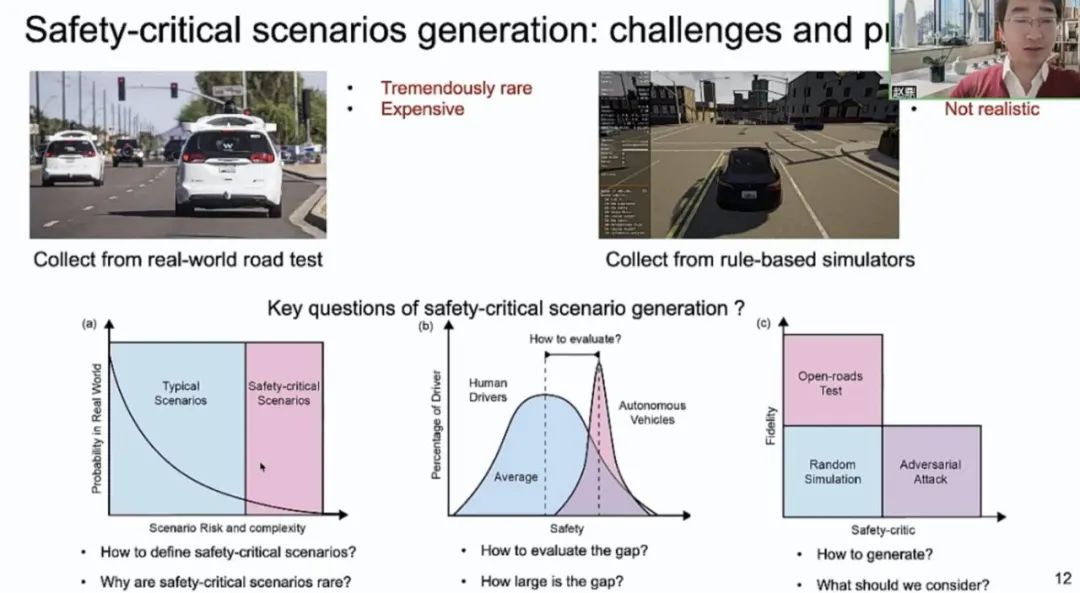
在自动驾驶相关领域中,大量工作已经利用真实行驶车辆与仿真器达成了驾驶场景生成,但其中对安全性意义重大的场景数量非常稀少,而这种场景正是评估自动驾驶车辆的关键所在👨🏻⚕️🙇🏻。生成此类场景,主要有以下几个关键问题需要解决🤑:如何定义对安全性意义重大的场景、为什么这些场景比较少见👩🏿⚕️,如何评估人类驾驶和自动驾驶安全性之间的差距、这种差距究竟多大,以及如何生成对安全性意义重大的场景、生成时应该考虑哪些问题✈️。
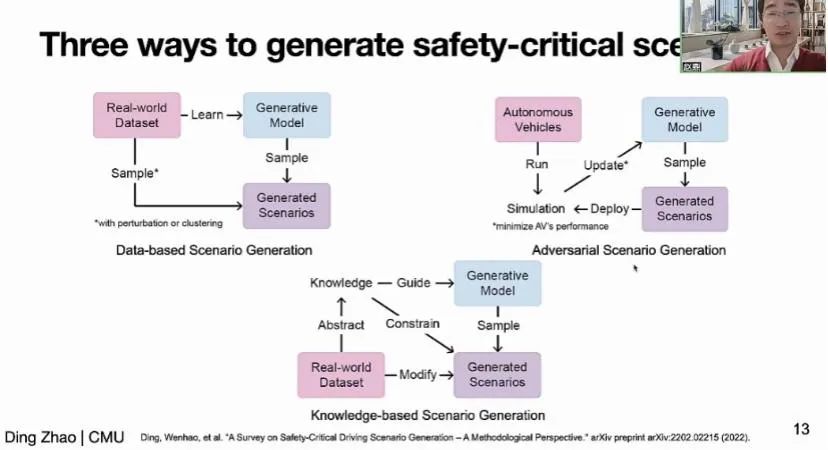
基于这样的背景🕵🏼♀️,赵鼎教授首先介绍了其在数字孪生生成方面的三类研究成果🧑🏽🍼:基于真实数据分布的生成式模型,基于对抗行为标准的生成式模型和融合了人类知识结构的生成式模型。
在第一类研究中🔣,赵教授团队构建了一系列从真实车辆轨迹数据中生成新的符合分布的新数据的方法👟,并且在极具挑战性的复杂交通场景中用非参贝叶斯方法寻找轨迹模式🏄🏻♀️。这一类研究方法使用了真实驾驶场景的数据,生成对安全性意义重大的场景时具有一定的可控性。但同时由于建立在已有数据的基础上🕥,该类方法生成的数据缺乏多样性🧜🏼♀️,且适应性较弱,缺少与下游任务的交互。
在第二类研究中,通过将多智能体环境中的其他智能体当成环境🎑,用与主智能体对抗的目标去优化其行为🧛🏼♀️,学习具有挑战性的驾驶轨迹,并验证了这种数据可以提升强化学习算法的鲁棒性。这类研究方法在一定程度上克服了第一类研究的局限性🙍🏻♂️8️⃣,生成的数据具有多样、多模态的分布形式,但面对差异性更大的环境时仍然有着低泛化性⛄️🎫、易违反交通规则等问题🦸🏻。
为进一步克服上述缺点,在第三类研究中,引入了关于真实世界数据、交通规则等信息的知识基础,利用树状变分自编码器建模人类知识结构,并将生成的轨迹往隐空间上进行投影,生成既符合特定数据分布又符合知识结构的轨迹👩🏽🎨。

赵鼎教授接着介绍了对于非平稳环境下安全可靠的强化学习算法的研究🧟♀️。虽然当前深度强化学习已经许多复杂任务的情景下展现了强大的能力👨🏽🔧,但将其部署到真实驾驶场景中的任务仍面对许多困难,如训练与测试环境不匹配🦡、存在安全性考虑等问题👭🏼。
为此赵鼎教授团队进行了一系列探索🧱,其中包括对在真实驾驶场景中部署算法时的延迟性的研究🤸🏻♀️。时间延迟在系统中的每一步运算都存在,通常对于安全性是不可忽视的因素。为缓解这一问题🦹🏽♂️🧏🏼,赵教授团队提出了延迟的马尔可夫决策过程,在面对时间延迟的情况下,其它现有算法效率大大降低,而本方法仍能取得接近无延迟情况下的上界。上述工作建立在系统已知存在延迟的情况下🏸,此外,在无法正确判断是否存在延迟时,团队使用了鲁棒的对抗式强化学习中的思路,同时针对其中存在的局限性🪓🤽♂️:对抗模型会产生极端困难甚至难以解决的环境使算法难以学习、简单梯度下降的训练方式不够稳定📝,提出了基于自适应正则对抗训练的斯塔克尔伯格博弈鲁棒强化学习方法,改善了先前工作的极端情况,取得了性能提升。
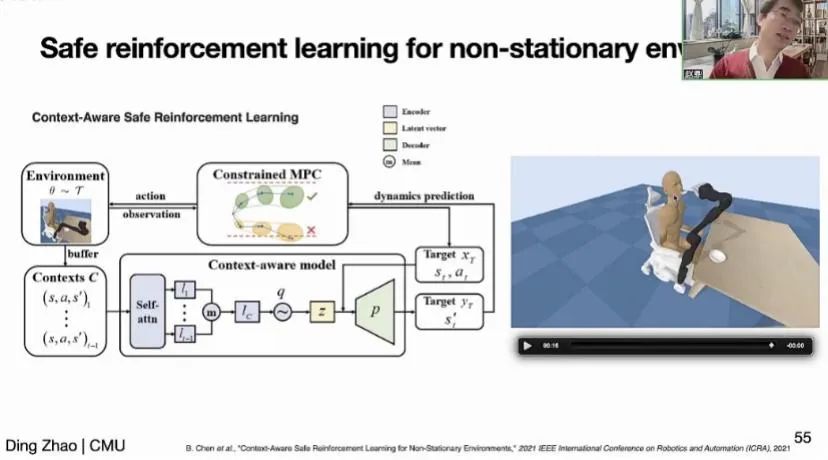
接着,赵鼎教授介绍了如何处理动态环境的问题。赵教授团队构建了一个机械臂喂食人类的仿真环境🎏,为了模拟失能人士的头部抖动,该环境用非平稳的模型建模头部轨迹。团队提出了一种新的算法模块👨🏼🚒,通过自注意力机制建模轨迹的上下文,并在强化学习的算法设计中讲失能人士的安全舒适性建模为奖励,训练出了能够跟随用户头部抖动的喂食策略🎭。在底层策略方面,利用带约束的运动预测控制算法精确建模所需的控制信号♻。
鼎教授最后介绍了其一系列加速测试的学术成果。随着自动驾驶汽车的性能提高🧑🦱,在真实环境中遇到安全挑战的概率也在降低🧌,测试难度随之提升🥔。与此同时,在真实环境中的安全测试面临无法克服的高成本和伦理问题🏋🏼♀️👨🍼,因此利用仿真环境加速测试是一个在科学和产业上都具有重要意义的方向🏃♂️➡️。赵教授团队将上述数字孪生构建和可靠强化学习算法的研究应用到自动驾驶场景中,构建了通用高效的测试框架🧑🏿🏫,得到了科学界和企业界的广泛认可🙎🏼。
精彩视频回顾及完整版PPT下载,请点击:
杏耀学术沙龙第17期 | 可信赖的AI及其在自动驾驶中的应用